End-to-End vs. ASR-LLM-TTS: Which One Is The Right Choice to Build Voice AI Agent?
The race to build the perfect Voice AI Agent has primarily split into two lanes: the seamless, ultra-low latency End-to-End (E2E) model (like Gemini Live), and the highly configurable ASR-LLM-TTS modular pipeline. While the speed and fluidity of the End-to-End approach have garnered significant attention, we argue that for enterprise-grade applications, the modular ASR-LLM-TTS architecture provides the strategic advantage of control, customization, and long-term scalability.
This is not simply a technical choice; it is a business decision that determines whether your AI Agent will be a generic tool or a highly specialized, branded extension of your operations.
The Allure of the Integrated Black Box (Low Latency, High Constraint)
End-to-End models are technologically impressive. By integrating the speech-to-text (ASR), large language model (LLM), and text-to-speech (TTS) functions into a single system, they achieve significantly lower latency compared to pipeline systems. The resulting conversation feels incredibly fluid, with minimal pauses—an experience that is highly compelling in demonstrations.
However, this integration creates a “black box”. Once the user's voice enters the system, you lose visibility and the ability to intervene until the synthesized voice comes out. For general consumer-grade assistants, this simplification works. But for companies with specialized vocabulary, unique brand voices, and strict compliance needs, simplicity comes at the cost of surgical control.
Lessons Learned from the Front Lines: The Echokit Experience
Our understanding of this architectural divide is forged through experience building complex, scalable voice platforms. In the early days of advanced voice interaction—systems like echokit—we tackled the challenge of delivering functional, high-quality, and reliable Voice AI using the available modular components.
These pioneering efforts, long before current E2E models were mainstream, taught us a crucial lesson: The ability to inspect, isolate, and optimize each stage (ASR, NLU/LLM, TTS) is non-negotiable for achieving enterprise-level accuracy and customization. We realized that while assembling the pipeline was complex, the resulting control over domain-specific accuracy, language model behavior, and distinct voice output ultimately delivered superior business results and a truly unique brand experience.
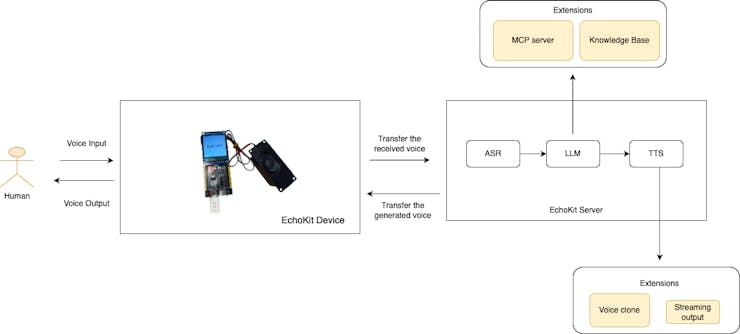
More importantly, EchoKit, which is open source, ensures complete transparency and adaptability.
The Power of the Modular Pipeline: Control and Precision (Higher Latency, Full Control)
The ASR-LLM-TTS pipeline breaks the Voice AI process down into three discrete, controllable stages. While this sequential process often results in higher overall latency compared to E2E solutions, this modularity is a deliberate architectural choice that grants businesses the power to optimize every single touchpoint.
- ASR (Acoustic and Language Model Fine-tuning): You can specifically train the ASR component on your industry jargon, product names, or regional accents. This is crucial in sectors like finance, healthcare, or manufacturing, where misrecognition of a single term can be disastrous. The pipeline allows you to correct ASR errors before they even reach the LLM, ensuring higher fidelity input.
- LLM (Knowledge Injection and Logic Control): This is the brain. You have the flexibility to swap out the LLM (whether it's GPT, Claude, or a custom model) and deeply integrate your proprietary knowledge bases (RAG), MCP servers, business rules, and specific workflow logic. You maintain complete control over the reasoning path and ensure responses are accurate and traceable.
- TTS (Brand Voice and Emotional Context): This is the face and personality of your brand. You can select, fine-tune, or even clone a unique voice that perfectly matches your brand identity, adjusting emotional tone and pacing. Your agent should sound like your company, not a generic robot.
Voice AI Architecture Comparison: E2E vs. ASR-LLM-TTS
The choice boils down to a fundamental trade-off between Latency vs. Customization.
| Feature | End-to-End (E2E) Model (e.g., Gemini Live) | ASR-LLM-TTS Pipeline (Modular) |
|---|---|---|
| Primary Advantage | Ultra-Low Latency & Fluidity. Excellent for fast, generic conversation. | Maximum Customization & Control. Optimized for business value. |
| Latency | Significantly Lower. Integrated processing minimizes delays. | Generally Higher. Sequential processing introduces latency between stages. |
| Architecture | Integrated Black Box. All components merged. | Three Discrete Modules. ASR $\to$ LLM $\to$ TTS. |
| Customization | Low. Limited ability to adjust individual components or voices. | High. Each module can be independently trained and swapped. |
| Brand Voice | Limited. Locked to vendor's available TTS options. | Full Control. Can implement custom voice cloning and precise emotion tagging. |
| Optimization Path | All-or-Nothing. Optimization requires waiting for the vendor to update the entire model. | Component-Specific. Allows precise fixes and continuous improvement on any single module. |
| Strategic Lock-in | High. Tightly bound to the single End-to-End vendor/platform. | Low. Flexibility to integrate best-of-breed components from different vendors. |
The Verdict: Choosing a Strategic Asset
While the ultra-low latency of an End-to-End agent is undoubtedly attractive, it is crucial to ask: Does speed alone deliver business value?
For most enterprise use cases—where the Agent handles critical customer service, sales inquiries, or technical support—the ability to be accurate, on-brand, and deeply integrated is far more valuable than shaving milliseconds off the response time.
The ASR-LLM-TTS architecture, validated by our experience with systems like echokit, is the strategic choice because it treats the Voice AI Agent not as a simple conversational tool, but as a controllable, customizable, and continuously optimizable business asset. By opting for modularity, you retain the control necessary to adapt to market changes, ensure data compliance, and, most importantly, deliver a unique and expert-level experience that truly reflects your brand.
Which solution delivers the highest long-term ROI and the strongest brand experience? The answer is clear: Control is the key to enterprise Voice AI.